Hi @Mari Clift, thank you for following up here. Our development team is still actively investigating this issue, I’m very sorry for the trouble and disruption here.
While they continue digging into this, they did recommend a few steps that may help performance in the meantime:
- If possible, could you please try this in incognito with a PDF file that has only a few pages?
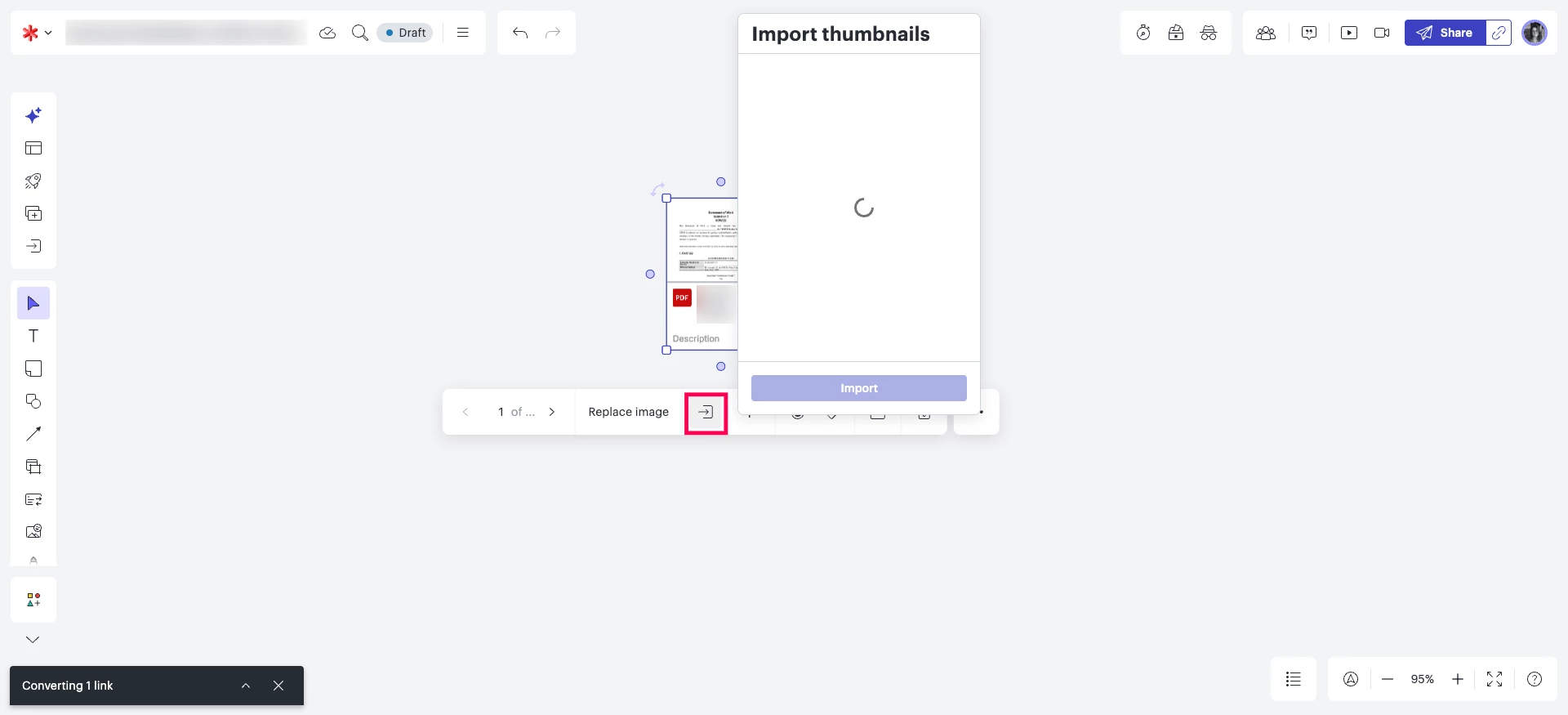
- Could you please try importing your PDF and waiting several minutes before attempting to extract thumbnails?
While this is not a perfect solution by any means, we’ve found that the specific steps above help to improve the performance here. While this is being worked on, we suggest trying the above to see if it helps you continue your work for the time being.
Please let me know if you have any additional questions. I will update this thread with any new information about a fix.