🌟 We just launched our JSON Import functionality within the Standard Import API, and it's set to revolutionize the way you create and visualize data in diagrams.
🔍 Why is JSON Import a Big Deal?
Simplicity and Power: Compared to other import methods, JSON import is less complicated yet more powerful, making it possible to auto-create detailed diagrams.
Fully Automated Workflow: You can now automate your entire diagram creation process more quickly. No need to open Lucid - just set up your JSON, send a request to our Import Document endpoint, and let Lucidchart handle the rest.
Ideal for Various Use Cases: Whether you're visualizing complex networks or leveraging AI for diagram creation, JSON import has opened up many new possibilities.
👥 Who Should Be Excited?
Network Professionals: Visualize intricate networks and data centers with ease.
AI Enthusiasts: Bring AI-generated diagrams to life quickly.
Automation Gurus: JSON import is the perfect option for automating workflows.
We're eager to see the innovative ways you'll use JSON import. Share examples of how you implement this new functionality or ask questions in the thread below this post.
For an example of how to use this new import, check out this Python project I built that imports completed Jira stories for a specified user. Before we had the Standard Import, we had to try to find this information through Jira and manually pull all the Jira tickets into a Lucid document for a user.
However, now that we have the Standard Import, this script can do all of that automatically. All you have to do is input the email of the Jira user, the year you want stories for, and which Lucid product you want to import them into. Then, the Python script will organize the stories by quarter and create a Lucid document for you.
This script has been super helpful for us going into year-end performance reviews so that we can see what work has been completed for each engineer on our team!
I created a document but page and shape data is getting ignored in my api calls, is there anything I can do to debug? I get a success message on the call.
Hi @jstockwell, thanks for following up in this post! Just to make sure we’re understanding your issue correctly, are you seeing an issue with none of your shapes/pages appearing when you’ve imported your JSON file or are you not seeing Custom shape and page data? Is it possible for you to share the format of your JSON file that corresponds to the issue?
This will allow us to take a closer look at what you’re experiencing! Thanks!
thanks, I have tried to copy the example in the JIRA example in the pinned post. I get a new document created with the correct title, but the page doesn’t get renamed and none of the shapes appear.
Another good resource to use if you want to use the standard import to create BPMN diagrams is this open source script my team and I created. It takes the route to the BPMN/XML file (or entire directory) you want to import, reads it, transforms it into the JSON format the standard import uses, and then makes the request to the API. This is still a work in progress but we are confident on how useful it is in it's current state!
Hi, @jstockwell , thanks for reaching out about the new Standard Import! I’m a developer on the team that built the import and can help you debug what’s going wrong. Me and a few of the engineers on my team just tried the import with the JSON that you sent over above and want to make sure we’re seeing the same thing as you.
This is a screenshot of the document that we got:
To get that doc:
I created a document.json file with the provided JSON in the post above
Compressed that single file into a zip archive
Renamed the zip archive to have the .lucid extension
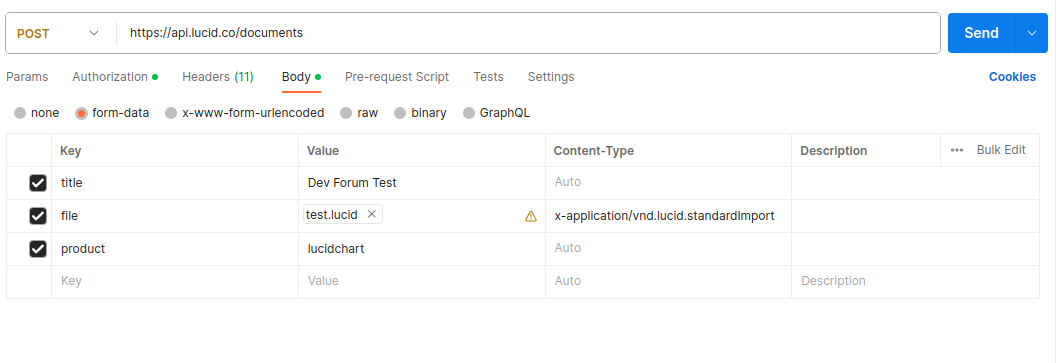
And sent a POST request using Postman to the https://api.lucid.co/documents endpoint. Here is a screenshot of the body of the request that I sent so you can check that we’re sending the same thing:
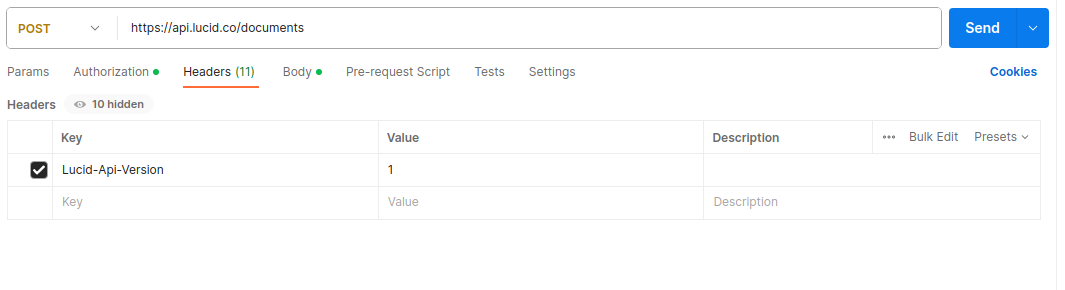
And here are the headers that I sent on that request:
Let me know if this matches what you are seeing and we can debug from there.
Hi, thanks for following up on this. I realised I’m missing the step of saving the json to a file/lucid document. I was trying to send the page and shape data as part of the body of the api data. I will try again with the file and see if this can resolve it.
Glad that we were able to find the missing step! Let us know if you have any more questions.
Hi!
I am trying to use Lucid Standard Import to create a document and I am getting “badRequest” with the following details:
{ "code": "badRequest", "message": "Bad or malformed request", "requestId": "6cfdf736169adfd9", "details": { "error": "Count: 1, message: Standard import file entry does not exist", "import_error_code": "invalid_file" } }
What should I do to fix it ?
Thanks!
Hi tuantv, thanks for reaching out! The error you’re seeing matches one that we’ve listed in the troubleshooting section of our documentation for the Lucid Standard Import that can be found here:
It appears that the problem might be happening because you compressed the folder containing your files instead of compressing the files together as a group.
If this isn’t the case, could you share your file structure so we can look into it further?
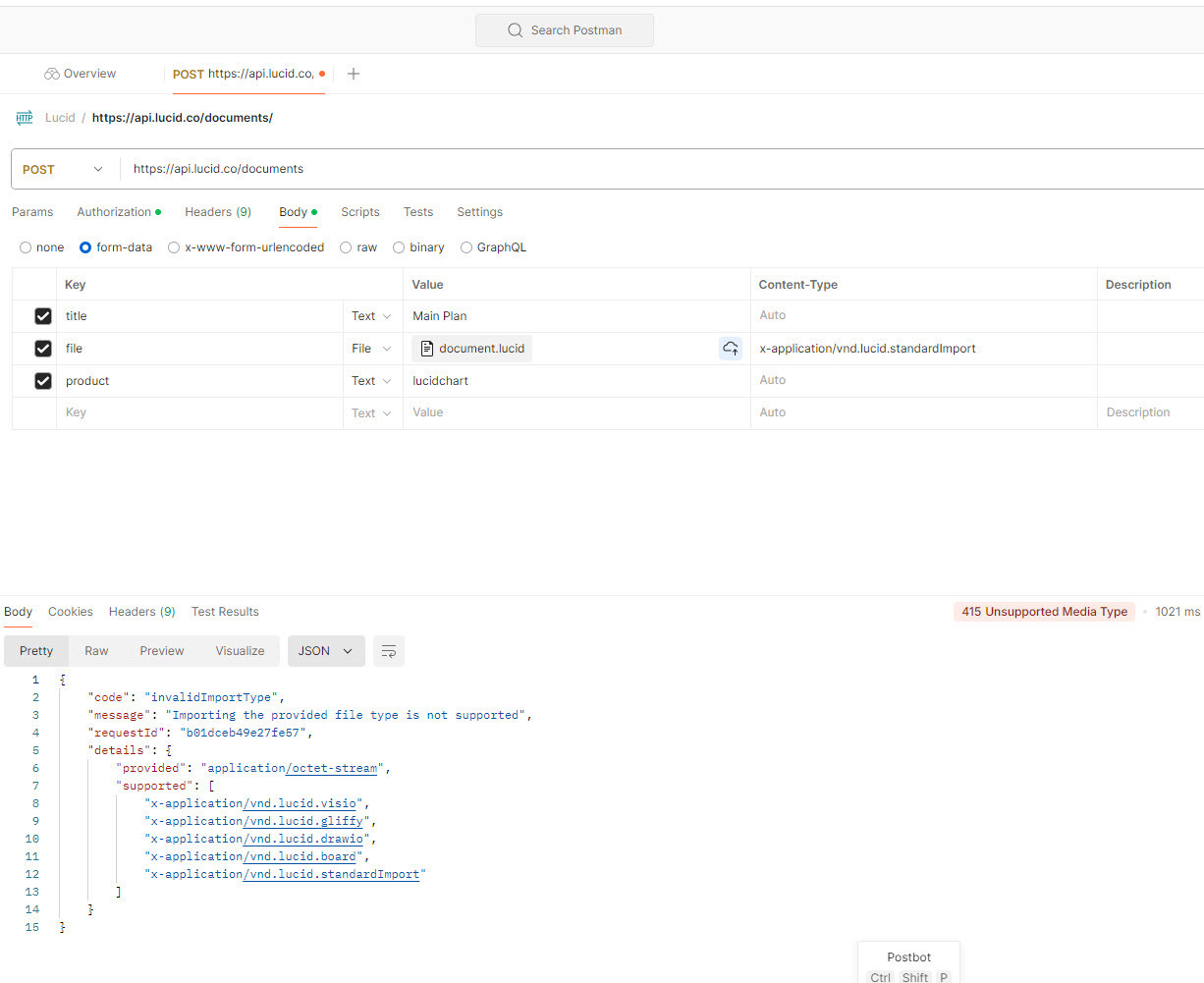
Hello, I am trying to replicate the file import steps and upload the example given above in this post using Postman and the endpoint: https://api.lucid.co/documents I did save the JSON in a document.json file, zipped it and followed your instructions as above:
Header:
Body:
When I send the request, I get an error, it looks like the file format is not recognized; I used “x-application/vnd.lucid.standardImport” as content-type for the file. I am working on Windows and use the build in Zip feature to generate this zipped file.
# Check the response print('Status Code:', response.status_code) print('Response:', response.text)
The response: Status Code: 400 Response: {"message":"Invalid Json: Unexpected character ('-' (code 45)) in numeric value: expected digit (0-9) to follow minus sign, for valid numeric value\n at lSource: (org.apache.pekko.util.ByteIterator$ByteArrayIterator$$anon$1); line: 1, column: 3]"}
Hi @eric_s , thanks for reaching out in this thread! Unfortunately, I’m unable to reproduce the error when I input the same values as you in your screenshot.
However, I am able to reproduce it when the import type has been inserted in the description field (and not content type). Could you double check to make sure there is nothing inserted in your description field? You may want to uncheck and recheck the content-type field to see if that helps.
Our API team were able to locate the logs for that endpoint and have confirmed that we are receiving the application/octet-stream as the Content-Type from that request. We have not made any changes to that value, which indicates that this is likely an issue of Postman not sending the value correctly.
In regards to your attempt at the import in Gitlab, could you try this with an Oauth 2.0 token instead an API key? I’ll also reach out to our API team to check this and will update here once we hear back.
Hello @Sylvia X Thank you! The following Python code works as expected GitLab, both with the API Key and Oauth 2.0 :
# Check the response print('Status Code:', response.status_code) print('Response:', response.text)
Hi @eric_s , thanks for following up here. It seems like this is working for you now. If this is not the case and you need further support, please let us know.
This would be so sweet to just work with a RESTful API and just add whatever you want to add on a canvas with just a POST request, without any JS browser involvement, SDK, zip files etc and a clear and simple JSON, using the same library that is available to do all that by hand.
Hi @diozsa , I agree! Lucid’s API’s helps take our visual collaboration suite to the next level. Stay tuned to the Lucid for Developers Community for updates to our developer platform!
Hi @diozsa , I agree! Lucid’s API’s helps take our visual collaboration suite to the next level. Stay tuned to the Lucid for Developers Community for updates to our developer platform!
Is there anything like that coming in the near future?
We are in the process of automating network topology diagrams dynamically and link them with the CI/CD flow in our ORG but at this current stage Lucid API is, the only thing that I can do is creating a doc and retrieving content via REST API. No editing possible.
The JSON formats required for import and what we get out with the export API are quite different (for instance keys / values such as “type” or “class”) ; ideally both formats would be compatible in order to speed up development of new objects - we could for example manually create diagrams and reuse (part of) the code in our imports - and eventually allow updating existing objects rather than creating new ones at each import
Hello Eric_s,
We completely agree. The two formats being different, and supporting different information, is problematic. Both in the ability to quickly spin up new projects and it limits the use cases available.
Unfortunately, unifying the two formats is not currently on the road-map. We do hope to provide a unified interface someday, but its not currently under development. If that were ever made available, the preexisting schematawould continue to be supported to ensure no existing applications were negatively effected.